Patient Matching Definition: What It Is And Why It Matters

Every time a patient visits a new clinic, fills a prescription at a different pharmacy, or gets lab work done at an outside facility, their health data lands in a separate system. Connecting those scattered records back to the right person is the core challenge behind patient matching definition, and it's a challenge that directly impacts care quality, billing accuracy, and patient safety. Without a reliable way to link records, clinicians make decisions with incomplete information, and organizations waste resources reconciling duplicate or mismatched data.
Patient matching sits at the foundation of healthcare interoperability. It determines whether two records in two different EHR systems actually belong to the same human being. Get it right, and data flows seamlessly between providers, payers, and applications. Get it wrong, and the consequences range from repeated tests and claim denials to dangerous medication errors.
For teams building healthcare applications that pull data from Epic, Cerner, Allscripts, or other EHR systems, understanding patient matching isn't optional, it's essential. At SoFaaS, we provide the managed SMART on FHIR infrastructure that connects your application to EHRs, and accurate patient matching is a critical piece of making those connections meaningful. This article breaks down exactly what patient matching is, how it works across systems, the algorithms and standards involved, and why it matters for anyone working in healthcare data integration.
Why patient matching matters for safety and interoperability
The full patient matching definition covers more than just linking records. It represents the process that determines whether your application treats two data entries as the same patient or two different people. When that determination fails, the downstream effects touch clinical decisions, financial operations, and regulatory compliance simultaneously. Healthcare organizations that underestimate this process expose themselves to both patient harm and significant operational cost.
Patient safety: the direct clinical impact
When a clinician pulls up a patient record, they trust that what they see is complete. If a matching error has merged records from two different patients, that clinician may see incorrect allergies, wrong medication history, or lab results that belong to someone else. The inverse problem, a single patient split across multiple records, means the clinician sees only part of the picture. They may order a test already completed, miss a critical diagnosis, or prescribe a drug that interacts badly with something recorded in a separate file.
Mismatched or fragmented patient records are a direct patient safety risk, not just a data quality inconvenience.
Research cited by the Office of the National Coordinator for Health Information Technology (ONC) has consistently pointed to patient matching failures as a root cause of preventable medical errors. These are not hypothetical edge cases. They happen regularly across health systems that rely on manual reconciliation or outdated matching logic. For your application to deliver reliable clinical value, the data it surfaces must belong to the correct patient, every single time.
Interoperability: the system-wide effects
Healthcare interoperability means different systems can exchange and use data meaningfully. Patient matching is what makes that exchange safe. Without accurate matching, data flowing between EHRs, payer systems, labs, and third-party applications creates more noise than signal. A unified view of a patient becomes impossible when each system holds a different version of who that patient is.
Financial and operational costs compound quickly. Duplicate records drive up administrative overhead, inflate payer audits, and trigger claim denials when patient identifiers don't align across systems. For health systems and vendors operating at scale, managing duplicate records costs millions of dollars annually in manual review and reconciliation work. When you build an application on top of EHR data, those duplicate records follow your data pipelines unless you address matching at the source.
Interoperability frameworks like FHIR are designed to move data efficiently between systems, but they depend on accurate patient identity resolution to function correctly. If your integration pulls records from Epic and Cerner for the same patient, but each system uses a different identifier, your application receives fragmented data that may appear complete but is actually missing critical context. That gap between apparent completeness and actual completeness is where matching errors become genuinely dangerous for both patients and the organizations responsible for their care.
The identifiers and data quality behind matching
Patient matching relies on a set of demographic data points to determine whether two records belong to the same individual. The quality of those data points directly shapes how well any matching system performs, whether you're running a deterministic algorithm, a probabilistic model, or a combination of both. Understanding what goes into the full patient matching definition means understanding which identifiers carry the most weight and where data entry problems introduce risk.
Core demographic identifiers
The identifiers most commonly used in patient matching include first name, last name, date of birth, sex, address, phone number, and Social Security Number (SSN). Many EHR systems also assign a Medical Record Number (MRN) that uniquely identifies a patient within that specific facility. When you query across multiple EHR systems, no single MRN follows the patient, so algorithms must fall back on demographic identifiers to establish a link.
Some identifiers carry more discriminating power than others. Date of birth and SSN together provide strong identifying signal because they rarely change and are specific to one individual. Name and address, by contrast, are more prone to variation across records.
The accuracy of any match is only as good as the data captured at intake, which means your matching logic must account for real-world inconsistencies from the start.
Why data quality determines matching success
Data entry at the point of care introduces misspellings, transpositions, and abbreviations that compound over time. A patient registered as "Katherine" in one system and "Catherine" in another creates a near-miss that deterministic matching will miss entirely. The same problem applies to addresses and phone numbers, which change frequently and often go unupdated in legacy systems.
Standardizing data before it enters your matching pipeline reduces error rates significantly. Techniques like phonetic normalization (Soundex or NYSIIS) and address standardization convert raw input into consistent formats that algorithms can compare reliably. When your application pulls data from multiple EHRs through a managed integration layer, applying these transformations upstream protects the integrity of every downstream query and clinical decision that depends on accurate patient identity.
How patient matching works across health systems
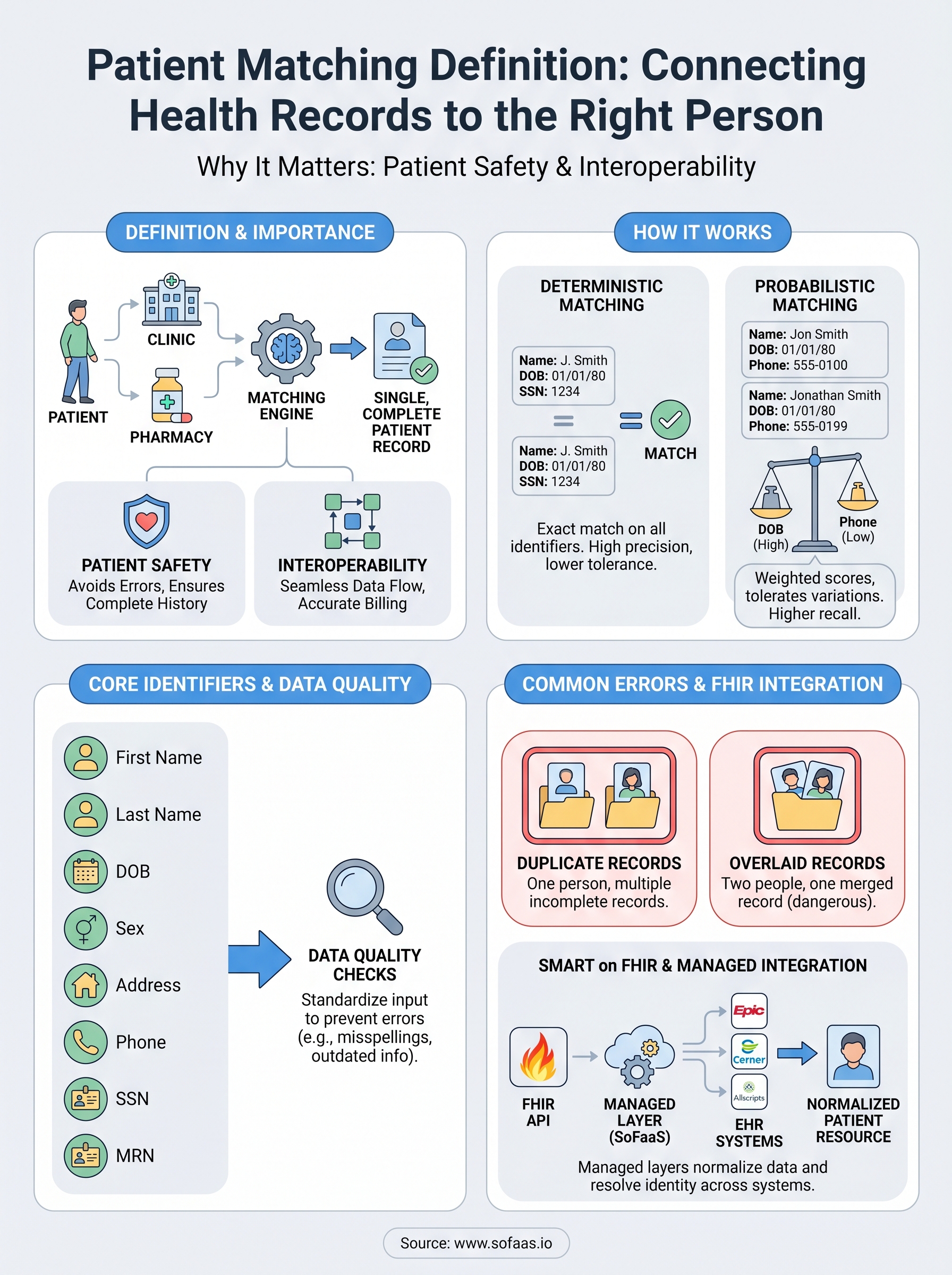
The full patient matching definition involves a deliberate, algorithmic process, not a simple database lookup. When your application queries patient records from multiple EHR systems, each system returns data formatted differently and anchored to its own internal identifiers. A matching engine sits between those systems and determines which records describe the same person. Two main approaches handle this work: deterministic matching and probabilistic matching. Most production systems use elements of both.

Deterministic matching
Deterministic matching compares specific fields and declares a match only when every selected identifier aligns exactly. If a patient's name, date of birth, and SSN all match across two records, the algorithm links them with high confidence. This approach works well when data entry is consistent and complete, which is rarely guaranteed across large health systems or networks of disparate facilities.
Deterministic matching produces high precision when identifier quality is high, but it fails silently when common data entry variations exist across records.
Probabilistic matching
Probabilistic matching assigns weighted scores to each identifier based on how much identifying power it carries. Date of birth might receive a higher weight than a phone number, because phone numbers change more often. The algorithm sums those weights and compares the result against a threshold score you define. Records above the threshold are linked; those below are flagged for manual review or rejected as non-matches. This approach tolerates the kind of real-world variation that defeats deterministic logic, including nickname use, address changes, and minor spelling differences.
How EHR queries complicate the process
When your application pulls data from Epic through one API endpoint and from Cerner through another, each system returns patient records with its own internal MRN and its own field formats. Your integration layer must normalize that data before any matching logic runs. Without normalization, a patient whose name appears as "Jon Smith" in one system and "Jonathan Smith" in another becomes two separate individuals in your data pipeline. Applying consistent field formatting and standardized demographic comparison before matching runs is the step that separates reliable integrations from fragile ones.
Common matching errors and how to prevent them
Patient matching failures cluster around a small set of repeatable problems. Understanding the full patient matching definition means recognizing not just what the process is, but where it breaks down in practice. Two errors account for the majority of real-world matching failures: duplicate records and overlaid records. Both carry serious risk, and both are preventable with the right processes in place.
Duplicate record creation
Duplicate records form when two entries exist in a system for the same individual, usually because intake staff could not locate an existing record and created a new one instead. This happens frequently during emergency registrations, after name changes, or when patients present without identification. Each duplicate captures only part of that patient's history, so any application querying that system returns incomplete data without any visible warning that something is missing.
You can reduce duplicate creation by implementing real-time matching checks at the point of registration, which surface potential existing records before a new one gets saved. Combining this with staff training on consistent data entry, particularly for names, dates of birth, and address formatting, cuts the rate of unintentional duplication significantly and protects the integrity of every downstream query your application runs.
Preventing duplicates at creation is far less costly than reconciling them across connected systems after the fact.
Overlaid records
Overlaid records are the opposite problem and significantly more dangerous. An overlay occurs when one patient's data gets written into another patient's record, effectively replacing or merging information that belongs to two different people. This typically happens when a registration clerk selects the wrong patient from a list of near-matches, especially when demographic data is sparse or inconsistently formatted across systems.

Catching overlays requires a different set of controls than catching duplicates. Your organization should implement audit logging at the record level so every write to a patient record carries a traceable identity and timestamp. Combining that with a probabilistic matching review step before any record merge is finalized gives you a second check that catches misidentification before it reaches downstream systems. When your application integrates with multiple EHRs through a managed layer, requiring explicit match confirmation before linking records across systems reduces your exposure to overlay errors substantially.
How to measure matching accuracy and risk
Any complete patient matching definition should include measurement, because a matching system you cannot evaluate is one you cannot improve. Two metrics form the core of matching accuracy assessment: false positive rate and false negative rate. A false positive links two records that belong to different patients; a false negative fails to link two records that belong to the same patient. Both errors carry real consequences, and tracking them separately helps you understand exactly where your matching logic needs adjustment.
Key metrics for evaluating match performance
Your matching system generates two distinct categories of error, and each one points to a different problem. False positives represent over-matching and carry the higher safety risk because they cause data from one patient to surface in another patient's record. False negatives represent under-matching and result in fragmented records that give clinicians an incomplete picture. Monitoring both rates consistently tells you whether your threshold settings are too aggressive, too lenient, or appropriately calibrated for your data environment.
| Metric | What it measures | Risk if high |
|---|---|---|
| False positive rate | Records incorrectly linked | Wrong patient data surfaces |
| False negative rate | Records incorrectly separated | Incomplete patient history |
| Match rate | Percentage of records successfully linked | Low rate signals data quality issues |
Managing risk at the integration level
Threshold tuning is the primary lever you control when adjusting probabilistic matching performance. Raising your match threshold reduces false positives but increases false negatives. Lowering it does the opposite. Finding the right balance requires running your algorithm against a representative test dataset that reflects the actual demographic variation in your patient population, not a clean sample that over-represents easy matches.
The only way to know whether your threshold setting is appropriate is to test it against real-world data and review the results manually.
Building a manual review queue for records that fall near your match threshold is equally important. Routing near-miss cases to a human reviewer rather than auto-accepting or auto-rejecting them keeps your match quality high without forcing you to push your threshold to a level that generates excessive false negatives across the board.
Patient matching in SMART on FHIR integrations
Any practical patient matching definition must address how matching operates inside real integration architectures, not just in theory. When your application connects to EHRs through SMART on FHIR, every patient data request triggers an identity resolution challenge that your integration layer either handles well or passes back to you as a problem. Understanding where matching sits in the FHIR data flow helps you build integrations that return accurate, complete patient records rather than fragmented or mislinked ones.
How FHIR handles patient identity
The FHIR standard includes a dedicated Patient resource that holds demographic identifiers for each individual in a system. When your application queries an EHR through a FHIR API, the response returns a Patient resource with fields like name, date of birth, address, and one or more system-specific identifiers, each scoped to the organization that issued it. A patient seen at three different facilities may have three different FHIR Patient resources, each with a separate MRN, and none of those identifiers carries over automatically to the others.
Resolving patient identity across FHIR endpoints requires explicit matching logic because FHIR itself does not guarantee a universal patient identifier.
FHIR also exposes a $match operation on the Patient resource, which lets your application submit a set of demographic parameters and receive back a list of candidate records with confidence scores attached. This built-in operation gives you a structured way to query for potential matches without writing a custom search from scratch, though the quality of results still depends entirely on how the underlying EHR populates its patient data.
What a managed integration layer does for matching
When you build on a platform like SoFaaS, the managed integration layer normalizes patient data across EHR systems before it reaches your application. That normalization step applies consistent field formatting, handles system-specific identifier mapping, and surfaces the right Patient resource for each query so your application does not have to reconcile raw differences between Epic's data model and Cerner's. Upstream normalization reduces the work your application logic must do and lowers the risk that matching errors slip through into clinical or operational workflows downstream.
Key takeaways
The full patient matching definition covers the process of linking health records across systems to the correct individual, and every section of this article connects back to that challenge. Accurate matching protects patients from receiving care based on incomplete or incorrect records, and it keeps your application's data pipelines free from duplicates and overlays that corrupt downstream clinical and operational decisions.
Your matching system's performance depends on three things: data quality at intake, algorithm calibration, and consistent measurement of false positive and false negative rates. Managing those variables well is what separates integrations that work reliably in production from ones that require constant manual intervention.
Building on SMART on FHIR simplifies the integration layer, but you still need upstream normalization and sound matching logic to surface accurate patient data. If you want to launch a SMART on FHIR integration that handles these challenges from the start, SoFaaS gives you the managed infrastructure to make it happen without building compliance and identity resolution from scratch.
The Future of Patient Logistics
Exploring the future of all things related to patient logistics, technology and how AI is going to re-shape the way we deliver care.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.