What Is Data Normalization? 1NF–3NF, Keys, And Dependencies

What Is Data Normalization? 1NF–3NF, Keys, And Dependencies
Healthcare applications pull patient records from Epic, Cerner, Allscripts, and dozens of other EHR systems, each with its own data structure. Without a consistent approach to organizing that information, you end up with duplicate entries, conflicting values, and databases that become nightmares to query. This is where understanding what is data normalization becomes essential for anyone building reliable healthcare software.
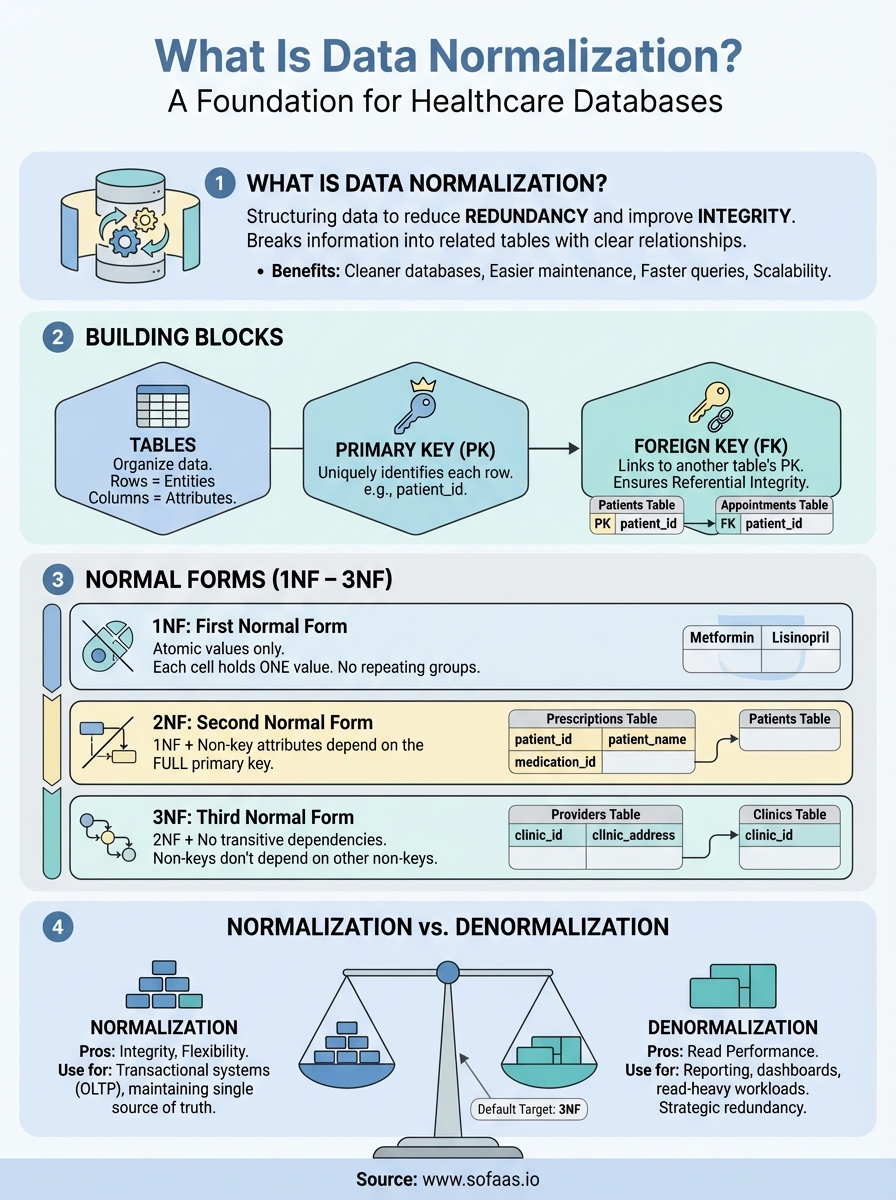
Data normalization is a database design technique that structures data to reduce redundancy and improve integrity. It breaks information into related tables, eliminates duplicate data, and establishes clear relationships through keys and dependencies. The result? Cleaner databases that are easier to maintain, update, and scale, exactly what you need when integrating patient data across multiple EHR systems through platforms like SoFaaS.
This article explains what data normalization is, why it matters, and how the three main normal forms (1NF, 2NF, 3NF) work. You'll learn about primary keys, foreign keys, and functional dependencies, the building blocks that make normalization possible. Whether you're designing a new database or optimizing an existing one for healthcare integration, understanding these fundamentals will help you build more efficient, reliable systems.
Why data normalization matters in real systems
Healthcare integration projects fail when databases store patient addresses in three different formats across multiple tables, or when updating a provider's phone number requires changing 5,000 records. These aren't hypothetical problems. They're daily realities for teams building applications that connect to Epic, Cerner, and other EHR systems. Understanding what is data normalization solves these issues by creating structured, maintainable databases that scale without breaking.
Data integrity breaks without normalization
Your database becomes a liability when the same patient information exists in multiple places with conflicting values. One table shows a patient's current medication as "Metformin 500mg," another lists "Metformin 500 mg," and a third says "Metformin ER 500mg." All three reference the same prescription, but your queries treat them as different medications. Unnormalized databases create these anomalies because they store redundant data that gets updated inconsistently across locations.
Normalization prevents update anomalies by storing each piece of information in exactly one place. When you change a patient's home address, you update a single record in a dedicated patient table instead of hunting through appointment records, billing entries, and care plans. This single source of truth eliminates conflicts and ensures that every part of your application sees the same data. Insertion anomalies and deletion anomalies also disappear when you structure data correctly, making your database more reliable from the start.
Normalized databases enforce data integrity through structure, not through constant manual checks and cleanup scripts.
Performance and storage costs
Redundant data wastes storage space and slows down queries. Your database stores the full provider name, clinic address, and specialty information with every single appointment record. A busy clinic with 50,000 appointments per year duplicates that provider data 50,000 times. When you normalize this structure, you create a providers table with one record per provider and link it to appointments through a simple foreign key. Storage drops dramatically, and queries run faster because the database processes fewer redundant bytes.
Query optimization becomes easier when your data follows a normalized structure. Database engines can use indexes more effectively on smaller, focused tables. Joins between normalized tables often perform better than scanning through massive unnormalized tables full of duplicate information. Your application responds faster when loading patient lists, scheduling appointments, or generating reports because the database works with clean, organized data instead of sorting through redundancy.
Maintenance and scalability challenges
Business rules change constantly in healthcare. A new regulation requires tracking additional patient consent types, or your organization expands to multiple states with different provider licensing requirements. Normalized databases adapt to these changes more easily because modifications happen in focused locations. You add a consent type to the consent_types table instead of altering hundreds of thousands of patient records scattered across your database.
Team productivity suffers when developers struggle with unnormalized schemas. New engineers joining your project spend weeks understanding why patient data appears in twelve different places, each with slightly different column names. Bugs multiply because updating logic in one area breaks functionality in another. Normalized structures create clear relationships between tables that developers grasp quickly, reducing onboarding time and minimizing errors. Your team ships features faster when the database design matches how the data actually relates in the real world, not just how it was convenient to store initially.
The building blocks: tables, keys, and dependencies
Understanding what is data normalization requires grasping three fundamental concepts that form the foundation of relational database design. Tables store your data, keys establish relationships between tables, and dependencies define how attributes relate to each other. These building blocks work together to create databases that maintain integrity and avoid redundancy. When you design a healthcare application pulling data from multiple EHR systems, these concepts determine whether your database becomes a reliable asset or a maintenance nightmare.
Tables as the foundation
Tables organize data into rows and columns, where each row represents a single entity and each column holds a specific attribute. Your patient table contains one row per patient, with columns for patient ID, name, date of birth, and contact information. Each table should represent one type of entity, not a mix of unrelated information. A poorly designed table might combine patient demographics, appointment details, and billing information in a single structure, creating redundancy and confusion.
Breaking data into focused tables gives you flexibility and clarity. Your application needs separate tables for patients, appointments, providers, medications, and diagnoses because these represent distinct entities with their own attributes. When you structure tables this way, updates become straightforward and your schema reflects the real-world relationships between healthcare data elements.
Primary and foreign keys
Primary keys uniquely identify each row in a table. Your patient table uses a patient_id as its primary key, ensuring no two patients share the same identifier. This unique constraint prevents duplicate records and gives other tables a reliable reference point when they need to link patient information. Every table in a normalized database requires a primary key that never changes and never contains null values.
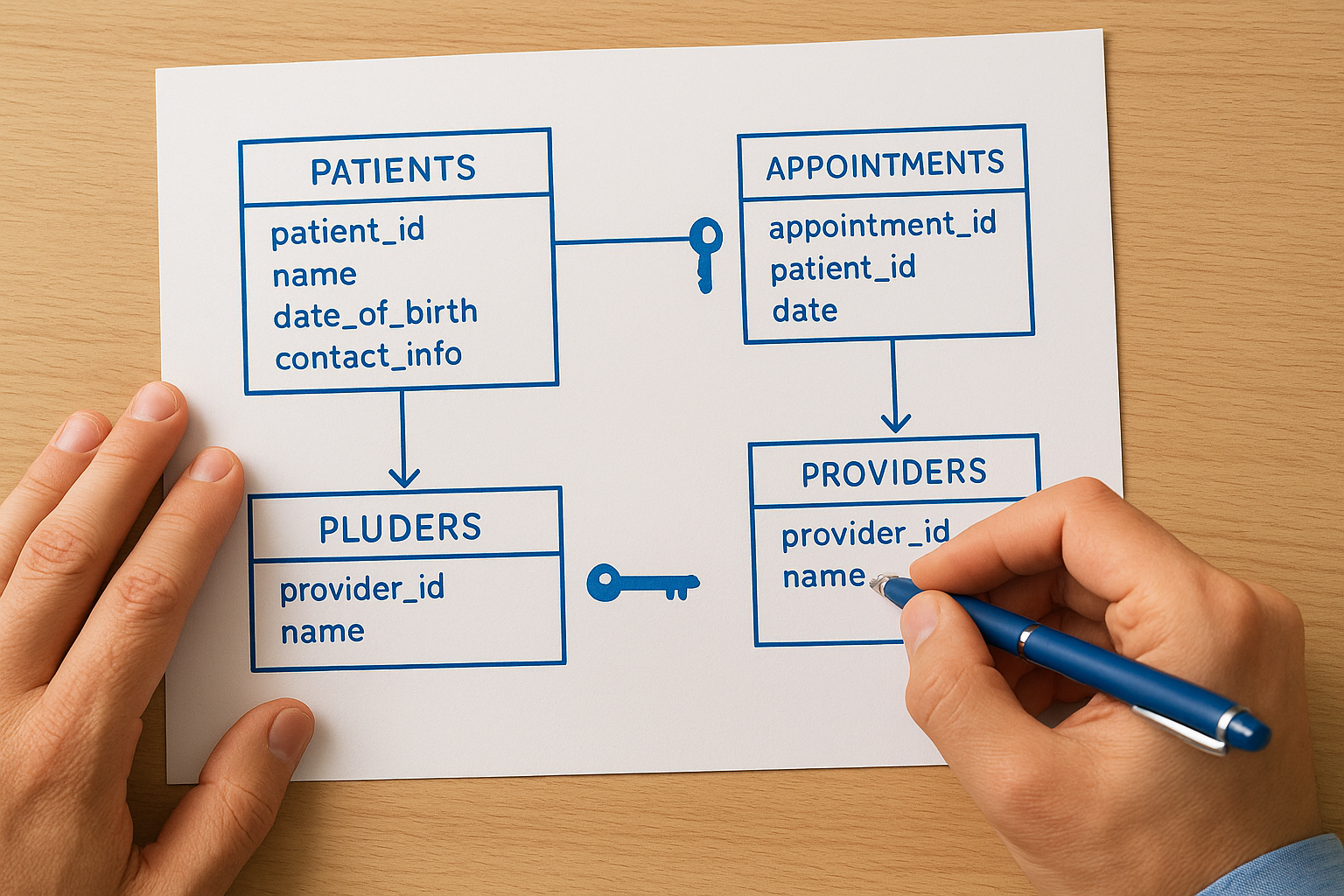
Foreign keys create relationships between tables by referencing another table's primary key. Your appointments table includes a patient_id column that stores values matching primary keys from the patient table. This foreign key establishes which patient belongs to each appointment without duplicating all the patient's demographic information. Foreign keys enforce referential integrity, preventing orphaned records where an appointment references a non-existent patient.
Keys transform isolated tables into a connected system where data relationships remain consistent and verifiable.
Functional dependencies
Functional dependencies describe how one attribute determines another within a table. When patient_id determines patient_name, address, and date_of_birth, these attributes are functionally dependent on the primary key. Understanding these dependencies helps you identify redundancy problems and organize data correctly across tables. A table where non-key attributes depend on each other rather than solely on the primary key signals normalization opportunities that improve your database structure.
Normal forms from 1NF to 3NF with examples
Understanding what is data normalization requires walking through the specific normal forms that define how you should structure your tables. Each normal form builds on the previous one, adding stricter rules that eliminate different types of redundancy and anomalies. Most production databases aim for third normal form (3NF) because it balances data integrity with practical performance. Healthcare applications dealing with patient records, appointments, and provider information benefit directly from these structures, especially when integrating data from multiple EHR systems.

First normal form (1NF)
Your table reaches first normal form when every column contains atomic values and each row is unique. Atomic means indivisible, a single value that can't be broken down further. A patient medications table violates 1NF when one column stores "Metformin, Lisinopril, Aspirin" as a comma-separated list. You fix this by creating separate rows for each medication, ensuring that every cell contains exactly one value that represents a single piece of information.
Repeating groups also break 1NF. Your appointments table shouldn't have columns named appointment_date_1, appointment_date_2, and appointment_date_3 to track multiple visits. This structure limits you to three appointments and makes queries complicated. Normalized 1NF design uses one row per appointment with a foreign key linking back to the patient. This approach handles any number of appointments without schema changes and makes your data easily queryable through standard SQL operations.
Second normal form (2NF)
Second normal form requires 1NF plus all non-key attributes must depend on the entire primary key, not just part of it. This matters when you use composite primary keys made from multiple columns. Your prescription table might use both patient_id and medication_id as a composite key, but then include a column for patient_name. That name depends only on patient_id, not the full composite key, which violates 2NF and creates redundancy.
Fixing 2NF violations means splitting tables so each non-key attribute depends on the complete primary key. You create separate tables for patients and medications, storing patient_name in the patients table where it depends on patient_id alone. The prescription table keeps only the relationship data between patients and medications, plus attributes like dosage and frequency that truly depend on both IDs together.
Each normal form eliminates a specific category of redundancy, making your database progressively more reliable and maintainable.
Third normal form (3NF)
Third normal form builds on 2NF by eliminating transitive dependencies where non-key attributes depend on other non-key attributes. Your provider table violates 3NF if it includes both clinic_id and clinic_address, because clinic_address depends on clinic_id rather than directly on the provider_id primary key. This creates update anomalies when clinic addresses change, requiring multiple row updates across all providers at that location.
Achieving 3NF requires moving transitively dependent attributes to their own tables. You create a clinics table with clinic_id as the primary key and clinic_address as an attribute. The providers table keeps only provider_id and clinic_id as a foreign key. Now updating a clinic address requires changing one row in the clinics table, and that change automatically applies to all providers associated with that clinic through the foreign key relationship.
Beyond 3NF: BCNF, 4NF, 5NF and tradeoffs
Understanding what is data normalization extends beyond third normal form into more specialized structures that address edge cases and subtle dependencies. Boyce-Codd normal form (BCNF), fourth normal form (4NF), and fifth normal form (5NF) define increasingly strict rules for organizing data. Most production databases stop at 3NF because higher normal forms solve rare problems that don't justify the added complexity. Healthcare applications dealing with straightforward patient records, appointments, and provider relationships rarely need these advanced forms.
Boyce-Codd normal form (BCNF)
BCNF strengthens 3NF by requiring that every determinant must be a candidate key. A determinant is any attribute that functionally determines another attribute. Your database violates BCNF when a non-key attribute determines part of the primary key. This happens in specific scenarios where a table has multiple overlapping candidate keys, creating subtle anomalies that 3NF misses.
Consider a table tracking which provider covers which clinic on specific days, using a composite key of clinic_id and day_of_week. If you add provider_specialty to this table and provider_id determines provider_specialty, you have a BCNF violation because provider_id isn't a candidate key. You fix this by creating a separate providers table where provider_id serves as the primary key and holds the specialty information.
Fourth and fifth normal forms
Fourth normal form eliminates multi-valued dependencies where one attribute determines multiple independent sets of values. Your provider table violates 4NF if a single provider has both multiple specialties and multiple clinic locations, stored as separate rows that create unnecessary combinations. Every specialty pairs with every location even though these attributes are independent.
Fifth normal form addresses join dependencies where you can decompose a table into multiple smaller tables and reconstruct it perfectly through joins. This form matters only in complex scenarios involving three or more relationships that interact in specific ways. Healthcare databases rarely encounter true 5NF violations because the relationships between patients, providers, medications, and facilities follow straightforward patterns that 3NF handles effectively.
Higher normal forms solve theoretical problems that most real-world databases never encounter, making 3NF the practical target for production systems.
When to stop normalizing
You stop normalizing when the benefits of data integrity no longer outweigh the costs of increased complexity. Every additional table and join adds query overhead and makes your schema harder for developers to understand. Healthcare applications need fast reads for displaying patient records, and excessive normalization can slow these operations by requiring multiple table joins to assemble basic information.
Performance considerations often justify stopping at 3NF or even strategically denormalizing certain tables. Your reporting queries might run faster with some calculated fields stored directly in tables rather than computed through joins. Balance normalization principles with actual system requirements, choosing structures that maintain integrity while delivering the query performance your application needs for daily operations.
Normalization vs denormalization in practice
Understanding what is data normalization becomes more nuanced when you consider that perfectly normalized databases aren't always the right choice for production systems. Real-world applications balance normalization's data integrity benefits against denormalization's performance advantages. Your healthcare application might normalize patient demographics while denormalizing frequently accessed appointment summaries that combine data from five different tables. The key is making deliberate decisions based on actual usage patterns rather than following normalization rules blindly.
When denormalization makes sense
Read-heavy applications benefit from strategic denormalization because joins slow down queries that run thousands of times per day. Your patient dashboard displays name, current medications, upcoming appointments, and recent vitals in a single view that would require joining six normalized tables. Storing a denormalized summary table that updates whenever these values change gives you instant dashboard loads without sacrificing data integrity in the underlying normalized tables. The denormalized version serves as a performance optimization, not the source of truth.
Reporting and analytics workloads almost always need denormalized structures. Your monthly provider performance report aggregates appointment counts, patient satisfaction scores, and billing totals across multiple dimensions. Running this report through normalized tables might take 45 seconds while users wait for results. Creating a denormalized reporting table that updates nightly reduces that query to under one second, making the report actually usable for daily decision-making without impacting your transactional database performance.
Strategic denormalization treats redundant data as a calculated field that improves performance without compromising the integrity of your normalized source tables.
Maintaining hybrid approaches
You maintain data integrity in hybrid systems by designating normalized tables as the authoritative source and treating denormalized tables as derived data. Your appointments table stays normalized with foreign keys to patients, providers, and clinics. A denormalized appointments_summary table duplicates patient names and provider specialties for quick lookups, but database triggers or application code updates this summary whenever the source tables change. This approach gives you fast reads without sacrificing the update simplicity that normalization provides.
Documentation becomes critical when you mix normalized and denormalized structures. Your team needs clear guidelines on which tables serve as source of truth and which exist purely for performance. Without this clarity, developers might update denormalized tables directly instead of modifying the normalized sources, creating data inconsistencies that undermine your entire architecture. Schema documentation should explicitly mark denormalized tables and explain the synchronization mechanisms that keep them aligned with normalized sources.
Final thoughts
Understanding what is data normalization gives you the foundation for building reliable healthcare databases that maintain integrity while scaling across multiple EHR integrations. The principles covered here, from basic table structures through third normal form, apply directly to applications pulling patient data from Epic, Cerner, and other systems. Your database design choices determine whether your application becomes easier to maintain or accumulates technical debt that slows every future feature.
Start with 3NF as your default target and denormalize strategically based on actual performance metrics, not assumptions. Healthcare applications need both data integrity for regulatory compliance and query speed for clinical workflows. Testing your schema with realistic data volumes reveals where normalization helps and where it creates unnecessary complexity.
Building healthcare integrations requires solid database foundations combined with efficient EHR connectivity. If you're developing a SMART on FHIR application and need to connect to multiple EHR systems without building integration infrastructure from scratch, launch your Smart on FHIR app through a managed platform that handles the complexity while you focus on normalized database design and application logic.
The Future of Patient Logistics
Exploring the future of all things related to patient logistics, technology and how AI is going to re-shape the way we deliver care.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.