Data Normalization Definition: Purpose, Forms, And Examples

Data Normalization Definition: Purpose, Forms, And Examples
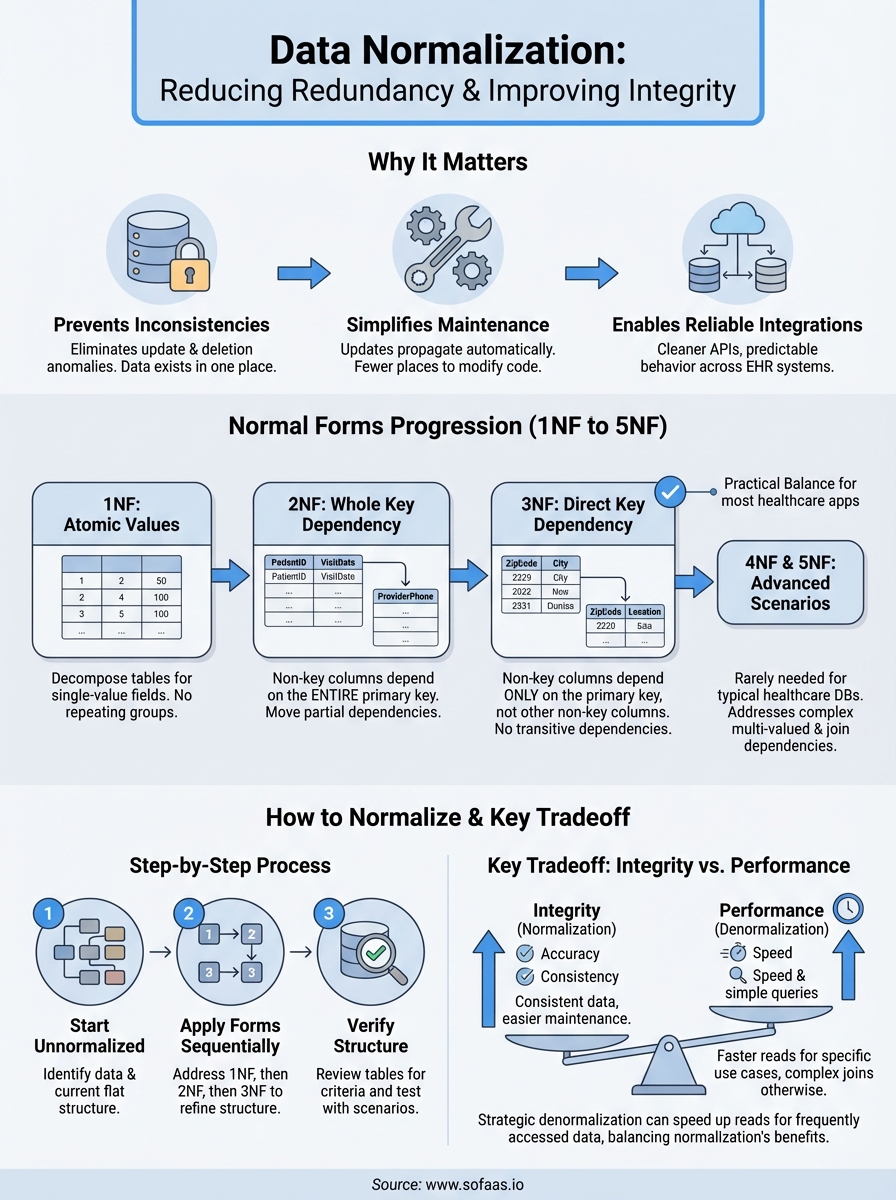
When patient records flow between different Electronic Health Records systems, inconsistent data structures can break integrations and compromise care coordination. Understanding the data normalization definition is essential for anyone building healthcare applications that need to work reliably across multiple data sources. At its core, normalization is the process of organizing data to reduce redundancy and improve integrity, a foundational concept that directly impacts how efficiently your systems handle information.
For healthcare developers connecting to EHRs through platforms like SoFaaS, normalized data means cleaner APIs, fewer edge cases, and more predictable behavior. Whether you're storing patient demographics, clinical observations, or billing codes, proper data structure matters. This article breaks down what data normalization actually means, walks through the different normal forms (1NF through 5NF), and provides practical examples you can apply to your own database design decisions.
What data normalization means and what it is not
Data normalization in database design refers to a systematic approach that structures your data to minimize duplication and maintain consistency across related tables. You organize information into logical groups, establish clear relationships between entities, and ensure that each piece of data exists in exactly one place. This process prevents anomalies that occur when you update, insert, or delete records, making your database more reliable and easier to maintain over time.
The core definition
The data normalization definition centers on decomposing tables into smaller, well-structured units while preserving the relationships between them. When you normalize a database, you apply a series of formal rules called normal forms that progressively eliminate different types of redundancy. Each normal form builds on the previous one, creating tighter constraints on how you can organize data. For example, if you store a patient's address in multiple tables across your healthcare system, changing that address requires updates in several locations, which increases the risk of inconsistencies.
Normalization enforces referential integrity through foreign keys that connect related tables. Instead of repeating a physician's name and credentials in every patient record, you create a separate physicians table and reference it using a unique identifier. This approach means you update the physician's information once, and that change propagates throughout your entire system automatically.
Proper normalization transforms chaotic, redundant data structures into clean, maintainable systems that scale with your application's needs.
What normalization is not
Normalization is not a performance optimization technique, even though many developers assume it speeds up queries. In reality, joining multiple normalized tables can sometimes slow down read operations compared to denormalized structures that store everything in one place. You normalize to improve data integrity and consistency, not to make queries faster. Performance tuning comes later through indexes, caching, and strategic denormalization where appropriate.
People also confuse normalization with data validation or cleaning. Normalization addresses how you structure tables and relationships, while validation ensures that individual values meet your business rules. You can have perfectly normalized tables filled with incorrect data, just as you can have valid data trapped in a poorly designed, redundant structure. The two concepts serve different purposes and work together to create reliable databases.
Additionally, normalization does not mean eliminating all redundancy at any cost. Some calculated fields or aggregates make sense to store even if you could derive them from other tables. Your application might need quick access to a patient's total number of visits without counting records across multiple tables every time. Strategic denormalization based on real performance requirements differs from poor initial design that duplicates data without purpose. Understanding these distinctions helps you make informed decisions about when to follow normalization rules strictly and when practical considerations justify exceptions.
Why data normalization matters
You face real consequences when your database structure allows duplicate or inconsistent information to spread across your system. The data normalization definition matters because it directly prevents these structural problems that corrupt your data integrity over time. Without normalization, you create situations where updating a patient's insurance provider in one table leaves outdated information in another, causing billing errors and potential compliance issues. Healthcare applications that connect to multiple EHRs through platforms like SoFaaS rely on consistent data structures to maintain accuracy across integrations.
Preventing data inconsistencies
Normalization eliminates update anomalies that occur when the same information exists in multiple locations. If you store a medication's dosage instructions in every prescription record rather than referencing a medications table, changing the standard dosage requires hunting through thousands of records. Your team will inevitably miss some entries, creating inconsistencies that could lead to incorrect patient care. Normalized structures ensure that each piece of information lives in one authoritative location, so updates propagate correctly throughout your system.
The same principle applies to deletion anomalies where removing one record accidentally destroys unrelated information. When you delete a patient's last appointment from a poorly designed table that also stores provider credentials, you lose the provider's data entirely. Normalization separates these concerns into distinct tables with proper relationships, protecting your data from accidental loss.
Properly normalized databases prevent the silent data corruption that occurs when your structure allows contradictory information to exist simultaneously.
Simplifying maintenance and updates
Your development team spends less time tracking down redundant data when your schema follows normalization principles. Changes to business rules, regulatory requirements, or clinical workflows require modifications in fewer places, reducing the risk of introducing bugs. When new HIPAA requirements mandate additional patient consent tracking, you add fields to a single consents table rather than updating dozens of denormalized structures scattered across your application.
Normalized databases also make onboarding easier for new developers who need to understand your data model. Clear relationships between tables create self-documenting structures that reveal how information connects, while redundant designs force developers to reverse-engineer implicit rules buried in application code.
Normal forms from 1NF to 5NF
The data normalization definition includes a formal hierarchy of rules called normal forms that you apply sequentially to eliminate specific types of redundancy. Each normal form addresses particular structural problems in your database design, building on the requirements of the previous level. You progress from first normal form (1NF) through fifth normal form (5NF), with most practical applications stopping at third normal form since higher levels address increasingly specialized scenarios that rarely occur in typical healthcare databases.

First normal form (1NF)
Your database achieves first normal form when each table cell contains atomic values rather than lists or repeating groups. If you store a patient's medications as "aspirin, lisinopril, metformin" in a single text field, you violate 1NF because that cell contains multiple values. Instead, you create a separate medications table with one row per prescription, ensuring each cell holds exactly one piece of information. This structure allows you to query, sort, and filter individual medications reliably without parsing comma-separated strings.
Second and third normal forms (2NF and 3NF)
Second normal form requires that every non-key column depends on the entire primary key, not just part of it. When you use a composite key like (patient_id, appointment_date), storing the patient's phone number in that table violates 2NF because the phone number depends only on patient_id. You move such partially dependent attributes to a separate patients table where they belong.
Third normal form eliminates transitive dependencies where non-key columns depend on other non-key columns. If your appointments table stores both zip_code and city, you create a transitive dependency because city depends on zip_code rather than the appointment itself. Normalized design moves this geographic data to a separate table that you reference by zip code.
Third normal form strikes the practical balance between data integrity and complexity for most healthcare applications that need reliable, maintainable structures.
Fourth and fifth normal forms (4NF and 5NF)
Fourth normal form addresses multi-valued dependencies where one attribute determines multiple independent sets of values. You rarely encounter this in typical healthcare schemas, but it appears when storing complex relationships like physicians who can perform multiple procedures at various facilities, where procedures and facilities are independent factors. Fifth normal form handles even more specialized join dependencies that occur when you can reconstruct information from multiple smaller tables without loss. Most developers never need these advanced forms unless dealing with complex many-to-many relationships with additional constraints.
How to normalize a database step by step
Normalizing your database follows a structured process that transforms raw data requirements into clean, organized tables. You start with your unnormalized data structures and apply each normal form in sequence, addressing specific types of redundancy at each level. This systematic approach ensures you catch structural problems early rather than discovering data integrity issues after your application goes into production.
Start with unnormalized data
You begin by identifying all the data elements your application needs to track and documenting them without concern for structure. For a healthcare scheduling system, this might include patient names, addresses, appointment times, provider information, and facility locations all listed together. Create a single flat table that shows how you currently store or plan to store this information, including any repeating groups or multi-valued fields. This unnormalized starting point reveals the redundancy patterns you need to eliminate through the data normalization definition principles.
Apply each normal form sequentially
Transform your structure by addressing 1NF requirements first, breaking apart any multi-valued fields into separate rows and ensuring atomic values in each cell. If your appointments table stores multiple insurance providers in one field, you split these into individual records with one insurance entry per row. Next, move to 2NF by identifying partial dependencies where columns rely on only part of a composite key, creating separate tables for those attributes. Continue to 3NF by removing transitive dependencies, ensuring each non-key column depends directly on the primary key rather than other non-key columns.
Sequential application of normal forms creates increasingly refined structures that eliminate redundancy while maintaining all necessary relationships between your data entities.
Verify your structure
Review each table to confirm it meets the normal form criteria you targeted, checking that primary keys uniquely identify records and foreign keys properly reference related tables. Test your design by running through common scenarios like adding new patients, updating provider credentials, or deleting cancelled appointments to ensure operations work correctly without creating anomalies. Document your relationships and constraints so your team understands how tables connect and what referential integrity rules your database enforces.
Practical examples, tradeoffs, and common pitfalls
Applying the data normalization definition to actual healthcare scenarios reveals both the benefits and challenges you face when structuring your database. You need to understand where normalization helps most, where it might create unnecessary complexity, and what mistakes developers commonly make when organizing their data. Real-world applications rarely achieve perfect normalization because practical constraints often require thoughtful compromises.
Real-world healthcare example
Consider a patient medications tracking system where you initially store prescription data in a single table with columns for patient name, medication name, dosage, prescribing physician name, and physician credentials. Normalizing this structure creates separate tables for patients, medications, physicians, and prescriptions. Your prescriptions table now uses foreign keys to reference the other entities, eliminating redundancy where physician credentials appeared hundreds of times. When Dr. Smith updates their board certifications, you modify one record in the physicians table instead of hunting through thousands of prescription entries. This normalized structure prevents situations where the same physician has different credentials listed across various records.
Performance vs. integrity tradeoffs
You sacrifice query performance when normalization forces complex joins across multiple tables to retrieve information that existed in one place before. Healthcare dashboards that display patient summaries with appointment history, current medications, and assigned providers require joining five or six tables, which slows down rendering compared to denormalized structures. Strategic denormalization makes sense for frequently accessed, read-heavy data that changes rarely. You might cache a patient's calculated risk scores in their primary record rather than computing them from normalized clinical observations every time someone opens their chart.
Effective database design balances normalization principles with measured denormalization where performance requirements justify storing derived or redundant data.
Common mistakes to avoid
Developers often over-normalize by creating excessive tables for data that naturally belongs together, making simple queries unnecessarily complicated. Breaking a mailing address into separate tables for street, city, state, and zip code when addresses always function as atomic units adds complexity without benefit. Another mistake involves partial normalization where you normalize some tables to 3NF but leave others in unnormalized states, creating inconsistent data quality across your application. You also risk introducing errors when you modify normalized structures without updating the foreign key relationships, breaking referential integrity that normalization was supposed to protect.
Key takeaways
Understanding the data normalization definition gives you the foundation to build healthcare databases that maintain integrity as they scale. You eliminate redundancy through systematic application of normal forms, starting with 1NF's atomic values and progressing through 3NF to remove transitive dependencies. Most applications stop at third normal form because it balances data integrity with practical complexity, though specialized scenarios may require higher levels.
Your normalized structures prevent update anomalies, simplify maintenance, and ensure consistency across your entire system. However, you need to recognize when performance requirements justify strategic denormalization for frequently accessed data. When you're building healthcare applications that integrate with multiple EHR systems, clean data structures become essential for reliable operations. Launch your Smart on FHIR app with VectorCare's platform that handles integration complexity while you focus on building normalized databases that serve your application's core functionality.
The Future of Patient Logistics
Exploring the future of all things related to patient logistics, technology and how AI is going to re-shape the way we deliver care.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.